

{{ v.name }}
{{ v.cls }}類
{{ v.price }} ¥{{ v.price }}

大家好,我是哪吒。
Kafka幾乎是當今時代背景下數據管道的首選,無論你是做后端開發、還是大數據開發,對它可能都不陌生。開源軟件Kafka的應用越來越廣泛。
面對Kafka的普及和學習熱潮,哪吒想分享一下自己多年的開發經驗,帶領讀者比較輕松地掌握Kafka的相關知識。
Apache Kafka是一個高吞吐量、分布式、可水平擴展的消息傳遞系統,最初由LinkedIn開發。它的目標是解決海量數據的實時流式處理和傳輸問題。
Kafka的核心思想是將數據轉化為流,并以發布-訂閱的方式傳遞。
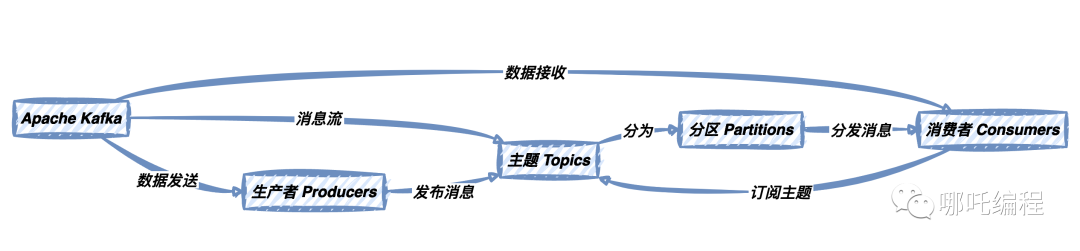
上圖描述了Kafka的核心概念和數據流向。從中可以看出,生產者將消息發布到主題,消費者訂閱主題并處理消息,而主題可以分為多個分區,以支持消息的并行處理和提高可伸縮性。
批處理和流處理是Kafka的兩種核心處理模式,它們在不同的應用場景中起到關鍵作用。理解它們的應用背景和差異有助于更好地利用Kafka的潛力。
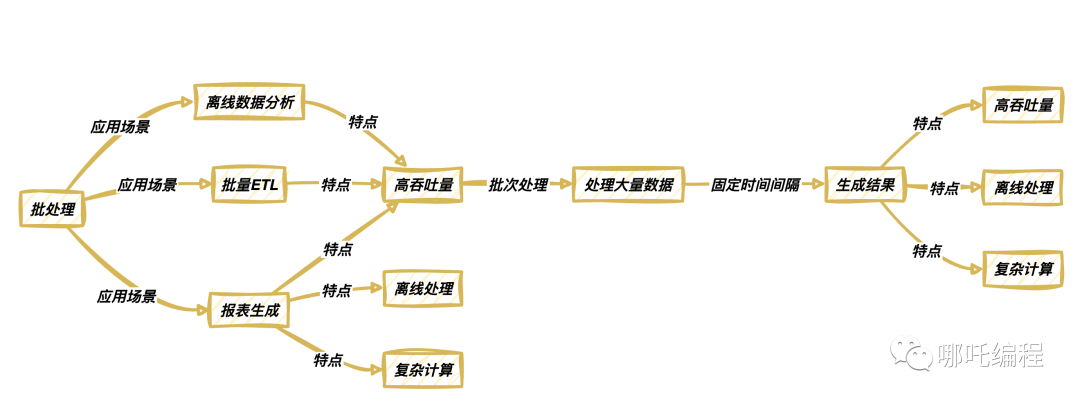
批處理是一種將數據按批次收集和處理的模式。它適用于需要處理大量歷史數據的任務,如報表生成、離線數據分析、批量ETL(Extract, Transform, Load)等。
批處理通常會在固定的時間間隔內運行,處理大量數據并生成結果。它具有以下特點:
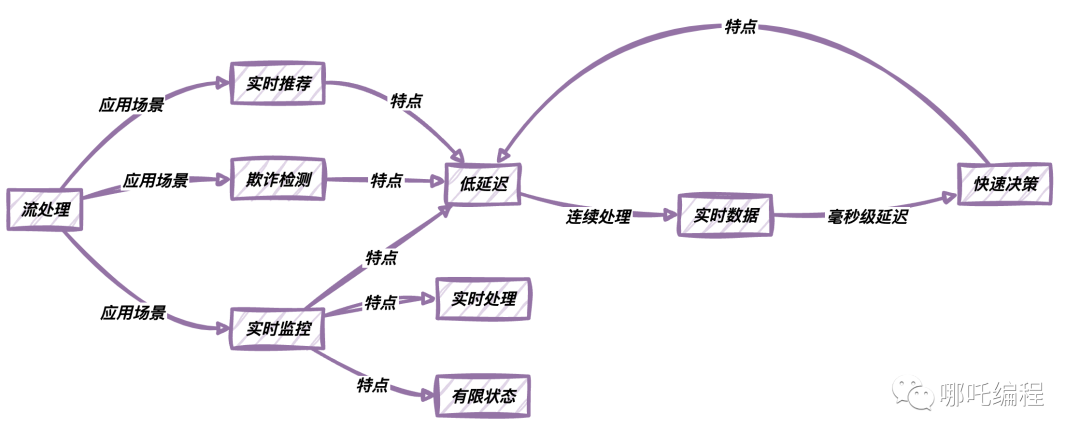
流處理是一種實時數據處理模式,它可以連續地處理流入的數據。它適用于需要實時響應的應用,如實時監控、實時推薦、欺詐檢測等。流處理使數據立即可用,它具有以下特點:
為了充分發揮Kafka的優勢,我們需要同時理解和使用這兩種模式,根據具體需求在批處理和流處理之間切換。例如,在大多數實際應用中,數據會以流的形式進入Kafka,然后可以通過流處理工具進行實時處理,同時,歷史數據也可以作為批處理任務周期性地處理。
Kafka默認的分區策略是Round-Robin,這意味著消息將依次分配給每個分區,確保每個分區接收相似數量的消息。這種默認策略適用于具有相似數據量和處理需求的分區情況。在這種策略下,Kafka會輪流將消息寫入每個分區,以保持負載的均衡性。對于大多數一般性的應用場景,這種默認策略通常已經足夠了。
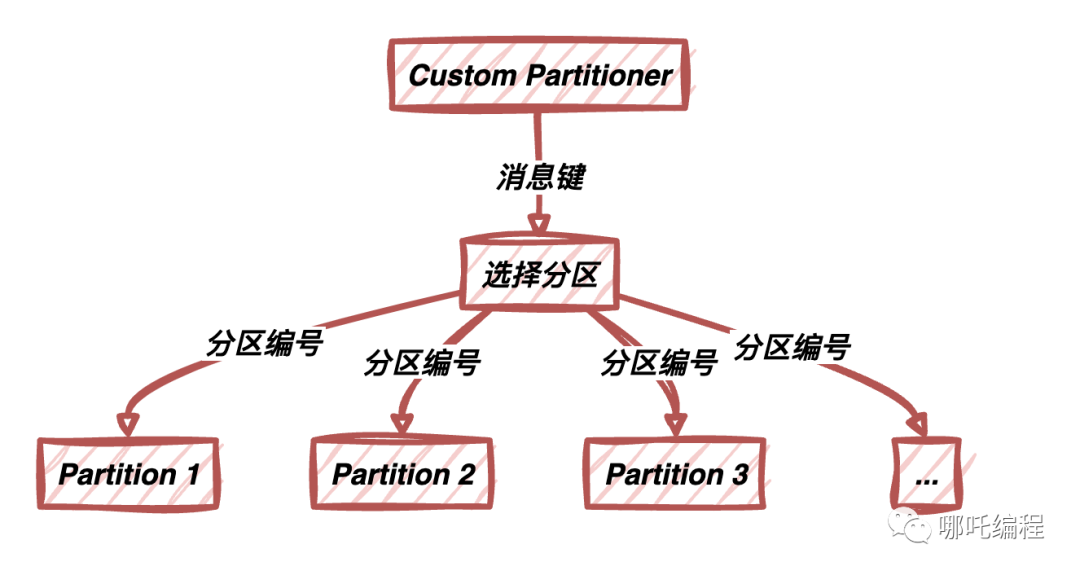
盡管默認分區策略適用于大多數情況,但有時候你可能需要更加靈活的分區策略。這時,你可以使用自定義分區策略,根據特定需求將消息路由到不同的分區。最常見的情況是,你希望確保具有相同鍵(Key)的消息被寫入到同一個分區,以維護消息的有序性。
自定義分區策略的示例代碼如下:
public class CustomPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); // 根據消息的鍵來選擇分區 int partition = Math.abs(key.hashCode()) % numPartitions; return partition; } @Override public void close() { // 關閉資源 } @Override public void configure(Map<String, ?> configs) { // 配置信息 } }自定義分區策略允許你更靈活地控制消息的路由方式。在上述示例中,根據消息的鍵來選擇分區,確保具有相同鍵的消息被寫入到同一個分區,以維護它們的有序性。
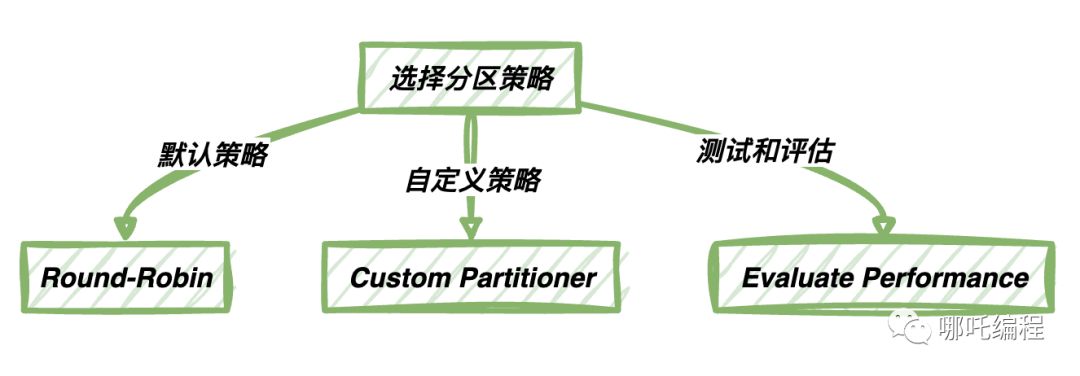
選擇分區策略應該根據你的具體需求和應用場景來進行。以下是一些最佳實踐建議:
選擇適當的分區策略可以幫助你優化Kafka的性能和消息處理方式,確保你的應用能夠以最佳方式處理消息。
批處理是一種數據處理方式,它按照固定的時間間隔或固定的數據量來收集、處理和分析數據。批處理適用于那些不需要實時響應的任務,如數據報表生成、大規模數據清洗、離線數據分析等。
在批處理中,數據通常存儲在一個集中的位置,然后周期性地批量處理。這個處理周期可以是每天、每周或根據業務需求的其他時間間隔。批處理任務會在處理過程中消耗大量資源,因為它需要處理整個數據集。
流處理是一種實時數據處理方式,它能夠連續地處理流入的數據。流處理適用于需要實時響應的應用,如實時監控、實時推薦、欺詐檢測等。
在流處理中,數據會立即被處理,而不需要等待批次的積累。這使得流處理能夠提供低延遲的數據處理,以滿足實時應用的要求。流處理通常用于處理事件流,監控傳感器數據等需要實時性的數據源。
批處理和流處理有以下區別:
為了充分發揮Kafka的優勢,你需要同時理解和使用這兩種處理模式,并根據具體需求在批處理和流處理之間切換。這將使你的應用能夠以最佳方式處理不同類型的數據。
批處理在許多應用場景中發揮著關鍵作用,特別是在需要處理大量歷史數據的任務中。以下是一些批處理應用場景的示例:
|
應用場景 |
描述 |
|
報表生成 |
每天、每周或每月生成各種類型的報表,如銷售報表、財務報表、運營分析等。 |
|
離線數據分析 |
對歷史數據進行深入分析,以發現趨勢、模式和異常情況。 |
|
數據倉庫填充 |
將數據從不同的數據源提取、轉換和加載到數據倉庫,以供查詢和分析。 |
|
大規模ETL |
將數據從一個系統轉移到另一個系統,通常涉及數據清洗和轉換。 |
|
批量圖像處理 |
處理大量圖像數據,例如生成縮略圖、處理濾鏡等。 |
典型的批處理架構包括以下組件:
|
組件 |
描述 |
|
數據源 |
數據處理任務的數據來源,可以是文件系統、數據庫、Kafka等。 |
|
數據處理 |
批處理任務的核心部分,包括數據的提取、轉換和加載(ETL),以及任何必要的計算和分析。 |
|
數據存儲 |
批處理任務期間,中間數據和處理結果的存儲位置,通常是關系型數據庫、NoSQL數據庫、分布式文件系統等。 |
|
結果生成 |
批處理任務的輸出,通常包括生成報表、填充數據倉庫等。 |
在批處理中,處理大量數據時需要考慮數據緩沖,以提高性能和有效管理數據:
狀態管理對于批處理非常關鍵,它有助于確保任務的可靠執行、恢復和容錯性:
錯誤處理是批處理過程中的關鍵部分,可以確保任務的可靠性和數據質量:
這些策略在批處理中的綜合使用,可以確保任務以可靠、高效和容錯的方式執行,滿足性能和質量需求。根據具體的應用場景,可以根據需求調整這些策略。
下面是一個簡單的示例,演示如何使用Kafka進行批處理。
public class KafkaBatchProcessor { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "batch-processing-group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Collections.singletonList("batch-data-topic")); // 批處理邏輯 while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { // 處理消息 processRecord(record.value()); } } } private static void processRecord(String record) { // 實現批處理邏輯 System.out.println("Processing record: " + record); } }在這個示例中,我們創建了一個Kafka消費者,訂閱了名為batch-data-topic的消息主題。消費者會定期拉取消息,并調用processRecord方法來處理每條消息。
這個示例展示了如何將Kafka用于批處理任務的數據源,但實際的數據處理邏輯可能更加復雜,具體取決于應用的需求。批處理任務通常會包括數據提取、轉換、處理和結果生成等步驟。
流處理適用于需要實時響應的應用場景,其中數據不斷流入系統并需要立即處理。以下是一些流處理應用場景的示例:
流處理應用通常需要滿足低延遲、高吞吐量和高可伸縮性的要求,以確保數據的及時性和質量。
流處理架構通常包括以下關鍵組件:
Kafka在流處理架構中常用作數據源和數據存儲,流處理框架用于處理數據流。這些組件共同協作,使流處理應用能夠實時響應和分析數據。
事件時間處理是流處理的重要策略,特別適用于需要處理帶有時間戳的事件數據的情況。事件時間表示事件發生的實際時間,而非數據到達系統的時間。流處理應用程序需要正確處理事件時間以確保數據的時序性。這包括處理亂序事件、延遲事件、重復事件等,以保持數據的一致性。
窗口操作是流處理的核心概念,它允許我們將數據分割成不同的時間窗口,以進行聚合和分析。常見的窗口類型包括滾動窗口(固定大小的窗口,隨時間滾動前進)和滑動窗口(固定大小的窗口,在數據流中滑動)。窗口操作使我們能夠在不同時間尺度上對數據進行摘要和分析,例如,每分鐘、每小時、每天的數據匯總。
流處理應用通常包括多個任務和依賴關系。管理任務之間的依賴關系非常關鍵,以確保數據按正確的順序處理。依賴處理包括任務的啟動和關閉順序、數據流的拓撲排序、故障恢復等。這確保了任務之間的一致性和正確性,尤其在分布式流處理應用中。
這些策略和關鍵概念共同確保了流處理應用的可靠性、時效性和正確性。它們是構建實時數據應用的基礎,對于不同的應用場景可能需要不同的調整和優化。
在這個示例中,我們演示了如何使用Kafka Streams進行流處理。以下是示例代碼的詳細解釋:
首先,我們創建一個Properties對象,用于配置Kafka Streams應用程序。我們設置了應用程序的ID和Kafka集群的地址。
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stream-processing-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");然后,我們創建一個StreamsBuilder對象,它將用于構建流處理拓撲。
StreamsBuilder builder = new StreamsBuilder();我們使用builder從名為stream-data-topic的Kafka主題中創建一個輸入數據流。
KStream<String, String> source = builder.stream("stream-data-topic");接下來,我們對數據流執行一系列操作。首先,我們使用filter操作篩選出包含"important-data"的消息。
source
.filter((key, value) -> value.contains("important-data"))然后,我們使用mapValues操作將篩選出的消息的值轉換為大寫。
.mapValues(value -> value.toUpperCase())最后,我們使用to操作將處理后的消息發送到名為output-topic的Kafka主題。
.to("output-topic");最后,我們創建一個KafkaStreams對象,將builder.build()和配置屬性傳遞給它,然后啟動流處理應用程序。
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();這個示例展示了如何使用Kafka Streams輕松地構建流處理應用程序,對消息進行篩選和轉換,然后將結果發送到另一個主題。這使得實時數據處理變得相對簡單,且具有高度的可伸縮性和容錯性。
數據流整合是將批處理和流處理相結合的過程。它允許在處理數據時,根據數據的特性切換處理模式,從而更好地滿足應用程序的需求。數據流整合可以通過使用不同的工具和庫來實現,以便在數據處理過程中無縫切換。
數據流整合通常需要進行數據轉換,以確保數據可以在批處理和流處理之間無縫流轉。這可能包括以下方面:
將數據從批處理傳遞到流處理,或反之,需要合適的數據傳遞機制。Kafka是一個出色的數據傳遞工具,因為它可以方便地支持數據傳遞。在Kafka中,批處理任務可以將數據寫入特定的批處理主題,而流處理任務可以從這些主題中讀取數據。這使得批處理和流處理之間的協同變得更加容易。
當你需要在實際應用中集成批處理與流處理時,下面是一些更詳細的操作步驟和示例代碼:
以下是一個簡單的示例,展示如何使用Kafka作為數據傳遞機制來集成批處理與流處理。假設我們有一個批處理任務,它從文件中讀取數據并將其寫入Kafka主題,然后有一個流處理任務,它從同一個Kafka主題中讀取數據并進行實時處理。
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.streaming.Duration; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import org.apache.spark.streaming.kafka.KafkaUtils; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import java.util.Set; public class BatchToStreamIntegration { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("BatchToStreamIntegration"); JavaSparkContext sparkContext = new JavaSparkContext(sparkConf); JavaStreamingContext streamingContext = new JavaStreamingContext(sparkContext, new Duration(5000)); Map<String, Integer> topicMap = new HashMap<>(); topicMap.put("input-topic", 1); JavaDStream<String> messages = KafkaUtils.createStream(streamingContext, "zookeeper.quorum", "group", topicMap) .map(consumerRecord -> consumerRecord._2()); messages.foreachRDD((JavaRDD<String> rdd) -> { rdd.foreach(record -> processRecord(record)); }); streamingContext.start(); streamingContext.awaitTermination(); } private static void processRecord(String record) { System.out.println("Batch processing record: " + record); } }import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.kstream.Consumed; import org.apache.kafka.streams.kstream.KStream; import java.util.Properties; public class StreamToBatchIntegration { public static void main(String[] args) { Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stream-to-batch-app"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("input-topic", Consumed.with(Serdes.String(), Serdes.String())); source.foreach((key, value) -> { processRecord(value); }); KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); } private static void processRecord(String record) { System.out.println("Stream processing record: " + record); } }這兩個示例演示了如何使用不同的工具來實現批處理與流處理的集成。
客服
微信
APP下載
工單
頂部